
The following sections describe the basic structure and hierarchy of all NeXus files. The reason for imposing some discipline in the data organization is so that people can easily navigate the files and understand their contents without external documentation. As far as possible, NeXus files should be self-describing, at least to those familiar with the experimental technique. The NeXus file structure is an agreement on what information is included and where, and in no way removes the basic portability of HDF files; generic HDF-aware visualization tools, file content listings and editing programs, etc., should still read the files without problem.
The following sections discuss in general terms the types of data objects stored in NeXus files and their organization. The section on NeXus contents will describe in more detail what goes where.
NeXus data files contain two types of entity: data items and data groups.
All NeXus data are stored as multidimensional arrays. These are equivalent to Scientific Data Sets in HDF4 and simple datasets in HDF5. The multidimensional data can have any data type (floating point, integer, character string etc.) and can be endowed with arbitrary attributes such as labels, units, calibration offsets etc.
In HDF4, we use SDS's even for storing scalar values even though this is much less efficient than using HDF Vdata. This is because we consider it important that all data can have at least the "unit" attribute defined, and the original versions of HDF4 did not support Vdata attributes. We were also concerned about the extra complexity in the NeXus API entailed by using more than one type of data object. In the HDF4 version, we make use of some "tricks" for improving the storage efficiency of SDS's, such as preventing the creation of default dimension scales, and increasing the size of the HDF header blocks. This is not a problem in the HDF5 version, which has a unified data model similar to the HDF4 SDS.
Attributes are extra information that are associated with particular data sets. They are used to annotate the data, e.g. with units or calibration offsets, and may be of any data type. In addition, NeXus defines other attributes that will be used to identify primary data signals, plotting axes etc. Finally, NeXus files will themselves be annotated with global attributes used to identify the NeXus version, file owner, etc.
NeXus data are linked together in groups, which can be thought of as folders or directories in a file system. HDF allows data objects to be linked to more than one group without occupying any more storage space. This mechanism is analogous to the linking (or aliasing) of files in Unix (or Macintosh) file systems, although no one instance of such a link can be considered the "parent" of the others.
We use NeXus groups in order to make the layout of NeXus files easy to understand. The advantage of such a hierarchical organization is most evident when a lot of information, e.g. instrument descriptions, is stored. If there is minimal information available, some of the hierarchy will appear redundant but, once the principles of the NeXus file organization are understood, it should be easy to identify and retrieve any information that is stored.
In addition to their regular names, groups can have class names. This allows us to use some object-oriented concepts in designing NeXus files as discussed in more detail in the next section.
NeXus groups can be assigned both names and classes. This allows us to use some object-oriented concepts in designing NeXus files. In particular, we use group classes to define the type of group object and its expected contents whereas the group name labels a particular instance of that object. In some cases, the groups will actually define physical objects, such as crystal monochromators or disk choppers. In others, the group will define a logical set of descriptive data.
Every NeXus group will be assigned both a name and a class. The class will define the expected contents of the group whereas its name identifies a particular instance of that class.
NeXus class names begin with NX followed without a break by a lower case word with underscores used to separate words. The NX class names are a defined part of the NeXus standard and may not be modified by the user. If the user wants to define their own classes, they must not use the NX prefix.
In general, there can be more than one group of the same class but is name must be unique within the group.
It is not necessary for every variable defined for a class to be present in every instance of that class.
In this section, we describe the group structure of NeXus files. It is important to remember that it is not necessary for all these groups to be present in each NeXus file. However, if they are present, their locations should conform to the layout below. The actual contents of these groups will be described in a later section.
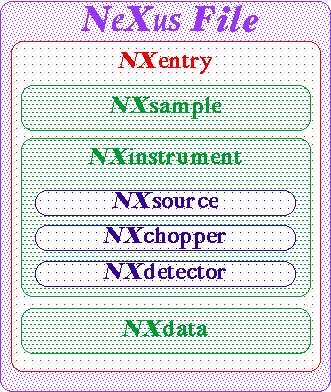
Although NeXus groups can have any descriptive name, their classes are restricted to those defined by the NeXus standard. These all have NX as a prefix. The following groups are examples of those typically found in each NeXus file. The links are to XML files in which the group contents are formally defined using the NeXus meta-DTD format.
| NXentry | ||
|---|---|---|
| All the data, including instrument and sample descriptions, which logically make up a single scan or measurement. At many facilities, this corresponds to the entity that is defined by a single run number, which could be used to name the NXentry group. There can be many NXentry groups in each NeXus file. | ||
| NXdata | The data to be plotted i.e. a single data set comprising the measurements along with the data errors, and the default axis scales and labels required to plot the data. There can be more than one NXdata group in each NXentry if there are several detector banks producing plottable data. | |
| NXsample | The information needed to define the physical state of the sample during the scan e.g. temperature, magnetic field, crystal mosaic. | |
| NXinstrument | The information needed to describe the instrument. In general, this group will contain several other groups describing the instrument components e.g. choppers, collimators, detectors. We give a few examples here of NeXus groups stored in the NXinstrument group. A comprehensive listing is given in the NeXus contents section. | |
| NXsource | The properties of the source that may be relevant for the experiment, such as the reactor power or the accelerator target material. This group could also contain logged data concerning the source performance such as the proton beam current. | |
| NXchopper | If users wants to store detailed instrumental descriptions with the NeXus data, they should store them in groups such as this. Each group corresponds to a beamline component of the instrument which has a defined position with respect to the sample position i.e. positive distances are downstream from the sample, negative are upstream. The sample has, by definition, a distance of zero. | |
| NXdetector | The information needed to describe the type, position, solid angle and efficiency of the detectors. It is also commonly used to store scattering angles and, in time-of-flight machines, the time-of-flight, since the time-gating of the measurements is a property of the detector counting chain. | |
The simplest HDF files conforming to the NeXus standard would consist of a single NXdata group contained within a single NXentry group. This would allow plotting programs to automatically select and plot the data but would not be sufficient for more detailed data analysis requiring instrumental and sample parameters.
One of the aims of the NeXus design was to make it possible for standard plotting applications to identify the plottable data automatically (or semi-automatically). Much of the data stored in NeXus files are meta-data i.e. not actual measurements but additional information required to interpret the data. In order to distinguish the actual measurements from this meta-data, it will be stored separately in groups with the class NXdata. The data defining the axis scales, i.e. the physical values corresponding to the data dimensions, will also be stored in the same group to make automatic plotting easier.
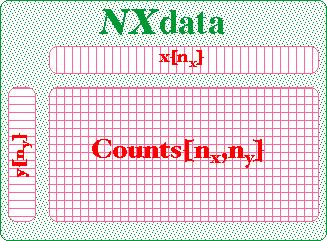
Each NXdata group will consist of only one data set containing plottable data and their standard deviations.
The data set will be identified by an attribute of "signal" given a value 1.
This data set may be of arbitrary rank.
If available, the standard deviations of the data are to be stored in a data set of the same rank and dimensions, with the name "errors".
For each data dimension, there should be a one-dimensional array of the same length.
These one-dimensional arrays are the "dimension scales" of the data i.e. the values of the independent variables at which the data is measured e.g. scattering angle or energy transfer.
There are two methods of linking each data dimension to its respective dimension scale.
data, with elements data[j][i] in C and data(i,j) in Fortran, where i is the time-of-flight index and j is the polar angle index, the NXdata group would contain :
<NXdata name="data">This attribute must be defined for each dimension scale.
<time_of_flight axis=1 primary=1> 1500.0 1502.0 1504.0 … </time_of_flight>
<polar_angle axis=2 primary=1> 15.0 15.6 16.2 … </polar_angle>
<data> 5 7 14 … </data>
</NXdata>
<NXdata name="data">The second method is required when the dimension scale is used in more than one NXdata group in a different context, e.g. it is used as the x-axis in one group and the y-axis in another.
<time_of_flight> 1500.0 1502.0 1504.0 … </time_of_flight>
<polar_angle> 15.0 15.6 16.2 … </polar_angle>
<data axis="[polar_angle,time_of_flight]"> 5 7 14 … </data>
</NXdata>
The first method was historically the first to be used, but the second is now recommended for future applications. However, both will be supported in NeXus utilities that identify dimension scales.
N.B. The "primary" attribute can only be used with the first method of defining dimension scales discussed above.
Technical Note
The NXdata group is only required because of limitations in the way HDF4 provides dimension scales. In HDF4, each dimension scale is a one-dimensional SDS which is linked to the data SDS by name rather than unique tag/reference pair. This means that it is not possible to have more than one dimension scale of the same name in the entire HDF file. This is an unacceptable limitation for the NeXus format. Instead, we identify dimension scales by their appearance in the same NXdata group and the value of their "axis" attribute. HDF5 has no standard way of identifying dimension scales
Any program whose aim is to identify plottable data should use the following procedure.
Consult the NeXus API section, which describes the routines available to program these operations. In the course of time, generic NeXus browsers will provide this functionality automatically.
Neutron counts are often stored as histograms. In time-of-flight measurements, the counts are collected in a set of contiguous time bins defined by the counting electronics. In position-sensitive detectors, the counts are collected in a set of contiguous detector pixels in either one or two dimensions. Although this is a very common state of affairs, very little software makes explicit use of the histogram nature of these counts even though it can make some operations, such as integration or unit conversion, much simpler to perform. It is not even easy to plot the data as histograms in many widely-used software packages.
As far as NeXus is concerned, the main problem that we must address is how to store histograms and their dimension scales. There are two issues: how to store the data (counts or distributions?), and how to store the dimensions scales (bin centers or bin boundaries?). Whichever we choose, it must be possible to read the data in the alternative form.
Comments to: Ray Osborn <ROsborn@anl.gov>
Revised: Saturday, September 14, 2002
Copyright © 1996-2002 NeXus Design Team. All rights reserved.